
Struggling with the second project of the Udacity course, image classification, it’s a key point to understand the process as a whole. Starting with:
1. What is a tensor?
First of all, consider everything in a graph mode.
TensorFlow is a programming system in which you represent computations as graphs. Nodes in the graph are called ops ( operations). An op takes zero or more Tensors, performs some computation, and produces zero or more Tensors. A Tensor is a typed multi-dimensional array. For example, you can represent a mini-batch of images as a 4-D array of floating point numbers with dimensions [batch, height, width, channels]

Then we can claim: TensorFlow ~ Tensor + Flow
I.e. tensors (units of array-like data) flowing through nodes (different kinds of operations, inner product, sigmoid, softmax, relu, etc), all the nodes forms a neural network graph. Demo of a small NN.
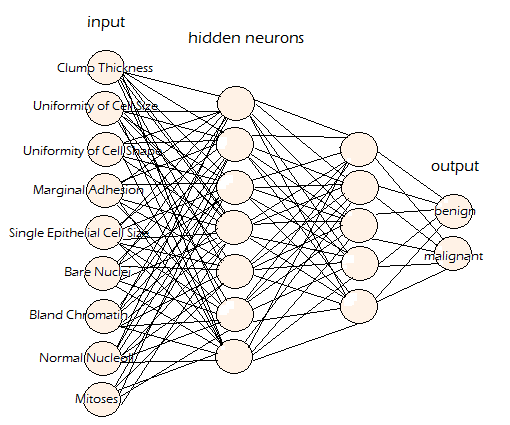
2. What is a session?
|
|
It’s actually bringing the graph framework into implementation.
On the other hand, like the lazy computation of Spark RDDs, tf.placeholder() simply allocates a block of memory for future use in sess.run(), thus the computation graph/pipeline can be built ahead of any real data flow. Example of some commands that are part of the graph:
|
|
|
|
3. Why CNN?
- Regular neural nets: nodes in a single layer are independent, will generate huge scale of weights.
- Full connectivity is a waste of “adjacent” info, number of parameters lead to overfitting.
- The depth of filter is just like different nodes in a single layer.(To capture different levels of info)
- Number of filters ~ depth of filters
- For the same filter (same depth), share all parameters. Example:
- Input shape 32x32x3 (H, W, D_Channel)
- 20 filters of shape 8x8x3, stride 2, padding 1.
- Output shape -> 14x14x20
- No P sharing: (8x8x3+1)x(14x14x20)
- With P sharing: (8x8x3+1)x20
